Richard Cubek
2013-04-28 18:06:11 UTC
Hello everyone,
I'm new to the list so first of all thanks a lot for your work on this
lib!
I need libsvm probability estimates as well as Logistic Regression (LR)
in a three classes problem with a training data set size of about 5-6000
at 20-50 features. I am familiar with python and octave (regarding math
even more with octave), but I would prefer python since I need all the
programming stuff which can be tedious in octave...
Reading lot of posts in discussions, scikit seems to offer the most
advanced and well documented python binding for libsvm, but I also found
following site:
http://fseoane.net/blog/2010/fast-bindings-for-libsvm-in-scikitslearn
He writes, that his bindings are implemented in scikit, but he also
writes, that the code is in alpha status, that was three years ago.
Well, I started with a simple problem with 65 data points with 2
features each.
Questions:
1) Playing around with svm probability, it "seems" to work nice
(Loading Image...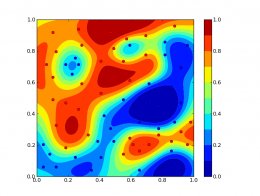 ). I just wanted
). I just wanted
to ask, how stable the python binding is regarding the website issue
mentioned above.
2) Playing around with LR, the results "look interesting"
(Loading Image...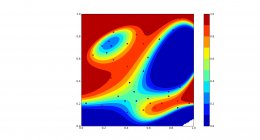 ), but I was
), but I was
not able to reproduce a model adopting/"overfitting" to every single
data point, as in the SVM example plot (tried very large C). I did the
first ML online class with Andrew Ng, there we implemented LR ourselves,
but the feature creation from the data features was ad hoc (from x and y
to x^2, y^2, x*y, x*y^2 and so on). I followed the same feature mapping
here, at the end getting 28 features out of 2. It takes about 15-17
seconds to fit the model (on my simple example).
I know feature selection/extraction itself is a big research topic, but
maybe scikit can help me here without the need to read a dozen papers or
maybe there are some rules of thumb. So is there any method within
scikit, that could help me finding a feature mapping? I guess, that
RandomizedLogisticRegression could help me somehow, but I didn't really
get the point. I think, here I again have to provide the features myself
and it will just help me finding the best by trying out randomly? On my
real data set, mapping the 20-50 features to higher-dimensional spaces
and trying out would probably take too long, if I consider the 15
seconds needed for a single model on the simple example (and here we are
not yet talking about searching the optimal regularization C). Any
suggestions?
Cheers!
Richard
I'm new to the list so first of all thanks a lot for your work on this
lib!
I need libsvm probability estimates as well as Logistic Regression (LR)
in a three classes problem with a training data set size of about 5-6000
at 20-50 features. I am familiar with python and octave (regarding math
even more with octave), but I would prefer python since I need all the
programming stuff which can be tedious in octave...
Reading lot of posts in discussions, scikit seems to offer the most
advanced and well documented python binding for libsvm, but I also found
following site:
http://fseoane.net/blog/2010/fast-bindings-for-libsvm-in-scikitslearn
He writes, that his bindings are implemented in scikit, but he also
writes, that the code is in alpha status, that was three years ago.
Well, I started with a simple problem with 65 data points with 2
features each.
Questions:
1) Playing around with svm probability, it "seems" to work nice
(Loading Image...
 ). I just wanted
). I just wantedto ask, how stable the python binding is regarding the website issue
mentioned above.
2) Playing around with LR, the results "look interesting"
(Loading Image...
 ), but I was
), but I wasnot able to reproduce a model adopting/"overfitting" to every single
data point, as in the SVM example plot (tried very large C). I did the
first ML online class with Andrew Ng, there we implemented LR ourselves,
but the feature creation from the data features was ad hoc (from x and y
to x^2, y^2, x*y, x*y^2 and so on). I followed the same feature mapping
here, at the end getting 28 features out of 2. It takes about 15-17
seconds to fit the model (on my simple example).
I know feature selection/extraction itself is a big research topic, but
maybe scikit can help me here without the need to read a dozen papers or
maybe there are some rules of thumb. So is there any method within
scikit, that could help me finding a feature mapping? I guess, that
RandomizedLogisticRegression could help me somehow, but I didn't really
get the point. I think, here I again have to provide the features myself
and it will just help me finding the best by trying out randomly? On my
real data set, mapping the 20-50 features to higher-dimensional spaces
and trying out would probably take too long, if I consider the 15
seconds needed for a single model on the simple example (and here we are
not yet talking about searching the optimal regularization C). Any
suggestions?
Cheers!
Richard